
From Workflow to Agent: A Migration Framework

Why Most Agentic-AI Migrations Fail in Phase Three
The operations director at a rapidly scaling logistics company found herself at a familiar inflection point. Her team had spent three years building an automation estate — hundreds of workflows orchestrating order processing, inventory updates, and customer notifications. The system worked, mostly. But the quarterly review revealed a troubling pattern: maintenance costs were climbing faster than transaction volumes, exception queues were backing up, and her engineering team was spending sixty percent of their time patching integrations that broke every time a vendor changed an API.
She understood, conceptually, that agentic AI offered something different — not just faster execution, but adaptive reasoning. What she lacked was a coherent path from where she was to where she needed to be, without shutting down the operations currently keeping the business running.
This is the problem most senior operations leaders face now. The direction is clear: deterministic, script-based automation is giving way to agentic systems that can reason, adapt, and handle ambiguity. The path between the two states is anything but obvious.
Why This Isn’t Just Automation 2.0
The first mistake organisations make is conceptual. They frame this transition as an upgrade, like moving between versions of software. The resulting migration plans look like replacement schedules: identify the workflow, build an agent to do the same thing, cut over on a weekend, decommission the old system.
This fails because it misunderstands what agentic systems are. Traditional automation encodes process knowledge as a fixed sequence. An RPA bot or scripted workflow is essentially a recording — frozen in time, brittle to change, dependent on interfaces remaining stable. When something unexpected happens, the automation fails or produces garbage. There is no recovery mechanism that wasn’t programmed in advance.
Agents operate on a different principle. They don’t execute predetermined sequences; they pursue goals using available tools, making real-time decisions based on context. An agent doesn’t know that a field moved on a form — it knows it needs to extract a customer reference number, and it adapts its approach if the interface has changed. When it hits an exception, it doesn’t necessarily fail. It evaluates whether the exception is within its handling parameters, and either resolves it or escalates with an explanation.
The shift from workflows to agents is not a technology upgrade. It is a paradigm shift from deterministic execution to goal-directed reasoning. That has profound implications for what you should even attempt to automate this way.
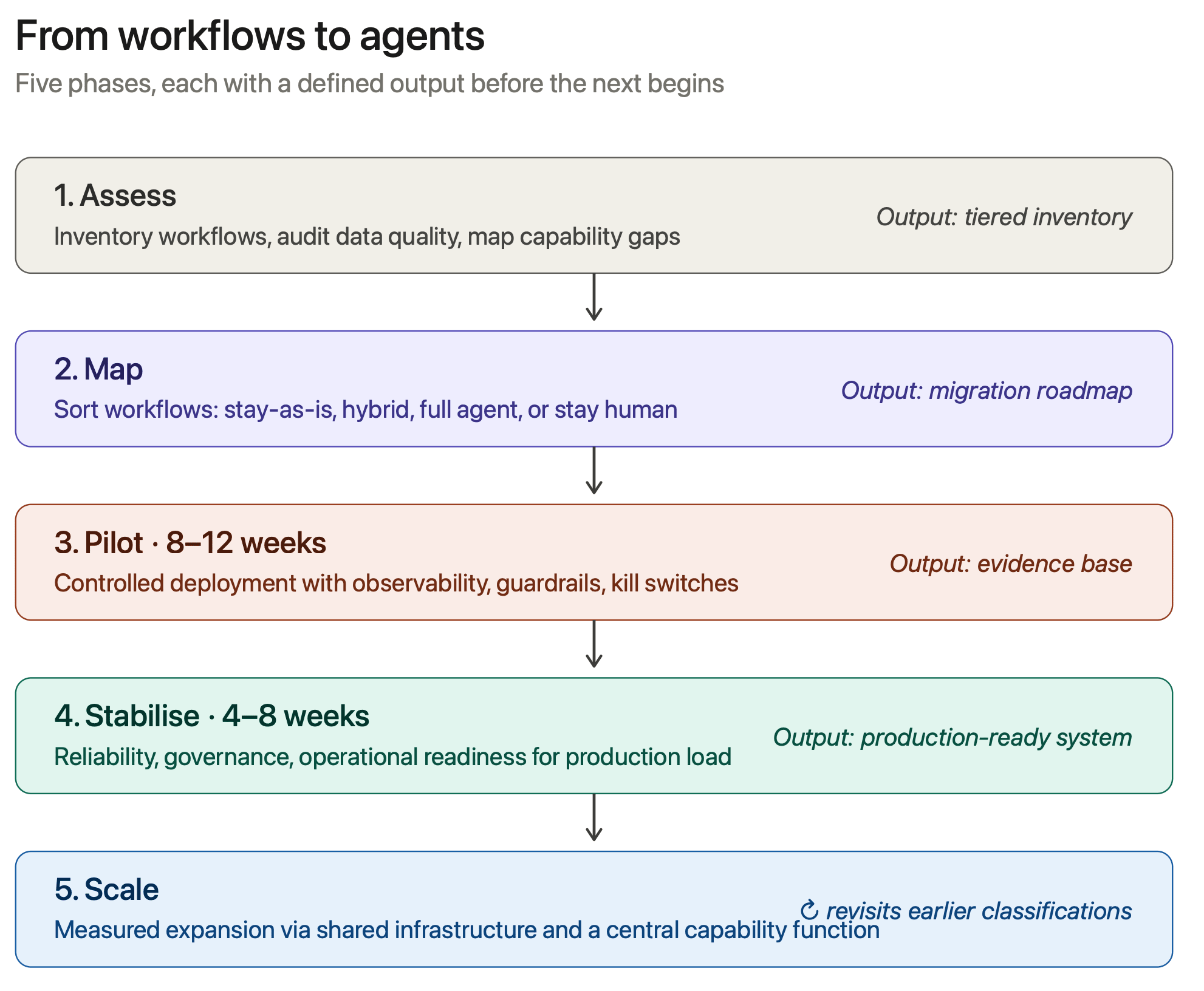
The Five Phases
A structured migration moves through five phases: Assess, Map, Pilot, Stabilise, Scale. Each has specific deliverables. Skipping or rushing through them is where most organisations accumulate the technical and operational debt that makes their agentic systems unstable in production.
Phase One: Assess
For our logistics director, the first temptation will be to start building. She should resist it. Before migrating anything, she needs an honest inventory.
The assessment phase produces three outputs. First, a complete catalogue of existing workflows — including the shadow automations that have proliferated in spreadsheets and personal scripts. Each should be characterised by stability rate, exception volume, strategic value, and integration surface area. Second, a data quality audit. Agentic systems are far more sensitive to data quality than traditional automation, because they make decisions based on the information available to them. Inconsistent customer records, duplicated product catalogues, or gaps in transaction logs will produce unpredictable agent behaviour — and these issues will become blocking problems in production if not addressed first. Third, a capability gap analysis. Traditional automation teams are usually strong on scripting, API integration, and orchestration. Agentic systems require additional capabilities: prompt engineering, tool design, behaviour specification, and observability for reasoning systems. Identify where these exist, where they need developing, and where external support is required.
Phase Two: Map
Not everything should become an agent. This is the most important principle in the framework, and the one most often violated. The goal is not to replace workflows with agents — it is to put the right kind of automation on the right kind of work.
The mapping phase sorts workflows into four categories.
High-stability, high-volume, low-exception processes should generally stay as traditional automation, or stay manual if volume doesn’t justify the build cost. These are predictable operations that don’t require judgment. Converting them to agents adds cost and complexity without adding capability.
High-stability processes with moderate exception rates are candidates for hybrid approaches. The core flow stays scripted; exception handling gets handed to an agent that decides whether to resolve or escalate. This preserves the efficiency of traditional automation while adding intelligence where it’s actually needed. For our logistics director, this is where most of her order-processing estate probably belongs.
Variable-input, judgment-required, high-exception processes are the primary agentic candidates. Customer inquiry triage, document analysis, complex order validation, exception resolution — workflows where the input is unstructured or the decision requires context. These are where agentic reasoning delivers genuine value over scripted logic.
Low-volume, strategic, high-risk processes should often stay human. The build and governance cost rarely justifies automating processes that run infrequently or where errors carry severe consequences. The temptation to automate everything should be resisted.
The output is a tiered migration roadmap: what stays as-is, what gets hybrid treatment, what becomes a full agentic system, and what stays human-led.
Phase Three: Pilot
This is where most migrations succeed or fail. The difference is discipline. A proper pilot is not a proof of concept — it is a controlled production deployment with strict boundaries, comprehensive observability, and a clear evaluation framework.
In one multi-agent deployment I worked on, the entire reply-routing logic depended on a single configuration value that wasn’t documented anywhere. The agents were technically working, but their outputs were going to the wrong threads. You don’t find that kind of failure mode in a design review. You find it by running the system and watching.
Pilot selection matters enormously. Choose a process representative of your agentic target category — variable inputs, judgment required, meaningful exception handling — but not on your most critical operational path. You want learning without existential risk. Pick a process where you have high-quality historical data and where stakeholders will tolerate iteration.
The implementation needs four components. Agent design and tool specification defines what the agent does, what tools it can use, what it can decide autonomously, and what must be escalated — plus the guardrails: rate limits, cost ceilings, prohibited actions, audit requirements. Observability infrastructure captures not just what the agent did but what it was reasoning about — the context it had, the decisions it considered and rejected. Building this after production is painful; it has to be part of the pilot. Safety mechanisms and kill switches detect anomalous behaviour, monitor cost, and impose human-in-the-loop checkpoints for high-stakes decisions. The goal isn’t preventing all failures — failures are how you learn — it’s containing them so they don’t cascade. Evaluation criteria defined upfront: performance metrics, operational metrics, qualitative assessments, and explicit failure criteria for when the pilot pauses or terminates.
Plan for eight to twelve weeks. The goal isn’t perfect day-one performance. It’s generating enough evidence about how agentic systems behave in your specific environment to make informed decisions about scaling.
Phase Four: Stabilise
A successful pilot doesn’t mean you’re ready for production. Pilots are controlled environments with more supervision than scaled deployment can sustain. Stabilisation hardens the system for production load with acceptable operational overhead.
Three focus areas: reliability engineering (addressing the failure modes and brittleness the pilot exposed, refining escalation logic, building runbooks for the operations team), governance integration (audit trails, access controls, change management for agent behaviour updates), and operational readiness (the team that will run this in production needs to be trained, equipped, and involved in stabilisation rather than handed a finished system).
Four to eight weeks, typically. Output: a production-ready system with documented reliability characteristics, integrated governance, and an equipped operations team.
Phase Five: Scale
Only now should you consider broader rollout. Scaling isn’t turning on agents everywhere at once — it’s measured expansion, learning from each deployment, building organisational capability as you go.
Follow the tiered roadmap from the mapping phase. Start with the highest-confidence, highest-value candidates. Each new deployment goes through a shortened pilot-and-stabilise sequence, tailored to the process but informed by the patterns established earlier.
Maintain a centralised capability function as you scale. Agentic systems share common infrastructure — observability platforms, tool libraries, governance frameworks, operational playbooks. A central team maintains these shared assets, captures learnings, and propagates best practices. Without this, each deployment becomes a bespoke project and you lose the efficiency that makes agentic automation scalable.
The scale phase is also where you revisit workflows initially classified as staying traditional. As your capability matures, some become candidates for hybrid or full agentic treatment. The migration is not a one-time event; it’s an ongoing capability evolution.
The Risks That Will Catch You
Four risks deserve specific attention, because they’re the ones operations leaders consistently underestimate.
Data quality failures are more damaging with agents than with traditional automation. Traditional automation fails predictably when data is bad — it errors, logs, stops. Agents may continue operating, making decisions on poor data, producing plausible-looking but wrong outputs. Your monitoring needs to be designed for agentic consumption, not just traditional database constraints.
Handoff failures are a major failure mode. When an agent escalates to a human, the context transfer has to be complete and comprehensible. If the operator has to reconstruct what the agent was trying to do, the handoff creates more work than it saves.
Trust deficits accumulate quietly. Visible early errors or heavy intervention requirements erode organisational confidence in ways that block future deployments even after the technical issues are resolved. Manage trust deliberately: set expectations, communicate transparently about both successes and failures.
Over-automation is a real risk. The capability to automate with agents leads to automating things that shouldn’t be automated — because the value doesn’t justify the cost, or judgment is genuinely required, or the process is too unstable to automate reliably. The mapping phase’s discipline has to be maintained throughout the migration.
Underlying all of this is the governance challenge: maintaining operational continuity while fundamentally changing how work gets done. You’ll have traditional workflows and agentic systems running side by side, sometimes within the same business process. That parallel operation requires clear ownership and reconciliation mechanisms. You’ll need genuine rollback capability — the ability to revert without data loss or operational disruption, which means keeping traditional workflows in a runnable state during transition. And you’ll need to preserve the organisational knowledge embedded in the workflows being migrated: the exception handling patterns, the business rules for edge cases, the rationale behind original design decisions. Agentic systems can obscure this knowledge if not designed with transparency in mind.
What You’re Really Building
The migration from workflows to agents isn’t ultimately about replacing one technology with another. It’s about building a new organisational capability: the ability to automate work that requires judgment, adaptation, and reasoning. This capability will become a core differentiator for organisations that get it right — and a source of fragility for those that don’t.
Assess, map, pilot, stabilise, scale isn’t a guarantee. It’s a structure for managing the uncertainty inherent in a paradigm shift. The details vary by organisation, industry, and the specific workflows being migrated. The principles don’t: be honest about your current state, be disciplined about what should become agentic, be careful in your early deployments, be patient about scaling.
What our logistics director is building isn’t just a more efficient back office. It’s the operational foundation for a different kind of organisation — one where human effort goes to work that genuinely requires human capability, and where the routine, the repetitive, and the resolvable are handled by systems that adapt as fast as the business environment changes. That is the promise of agentic automation. The framework is how you get there without breaking what you already have.