
Debugging AI Agent Infrastructure: A Real-World Case Study

It was a Tuesday morning. The AI agent responsible for routing and triaging a client’s incoming operational requests had been running reliably for six weeks. Tickets were processed. Tasks were delegated. Summaries arrived in the right Slack channels on schedule. Everything looked fine from the outside.
Except it wasn’t. Somewhere in the previous 48 hours, the agent had entered a degraded state. It was still running. It was still producing outputs. But it was quietly making decisions based on stale context — a memory structure that had stopped updating correctly after a schema change in an upstream data feed. The outputs were plausible. They just weren’t right.
Nobody flagged it immediately, because there were no error logs. No exceptions. No alerts. The system was functioning — it was just functioning incorrectly, and with enough surface plausibility to pass casual inspection. It took a domain expert reviewing a specific set of outputs to notice that the agent’s routing decisions over the prior two days had introduced systematic errors into a workflow that, uncorrected, would have required significant manual remediation.
That incident taught me more about AI agent infrastructure than any conference talk or research paper ever has.
This article is about what I learned, how I think about diagnosing agent failures now, and what any technical leader deploying agentic AI systems needs to understand about the specific ways these systems break — and why those failures are harder to catch than the ones we’re accustomed to.
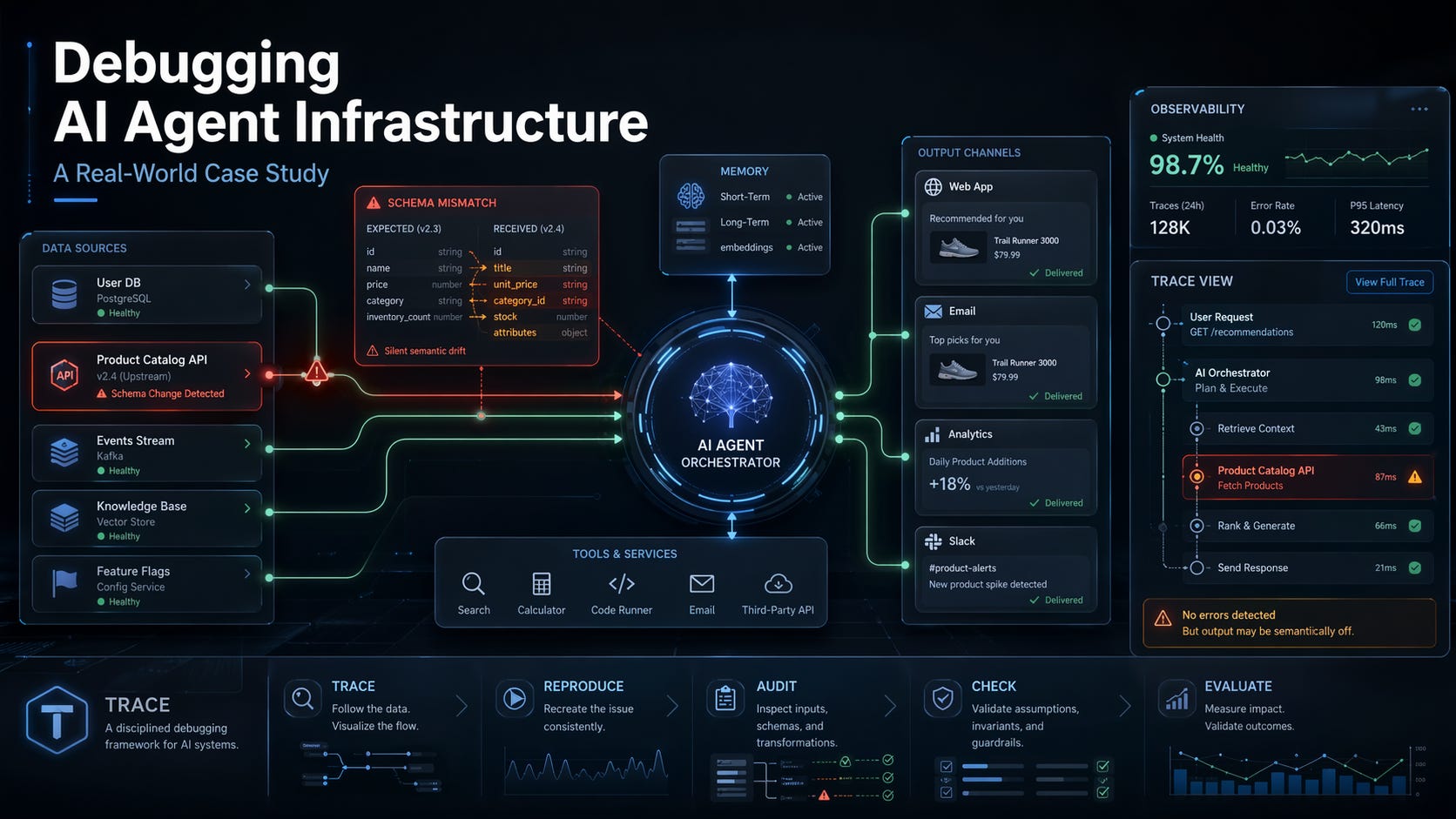
Why Agent Failures Are Different
When a traditional software service fails, the failure is usually legible. A database connection drops. An API returns a 500. A queue backs up. The system tells you something is wrong through well-established signals: error codes, stack traces, degraded response times. Monitoring and alerting for these failure modes is mature. We have decades of practice at it.
AI agents — particularly LLM-based agents with memory, tool access, and multi-step reasoning — fail differently. They fail softly. The outputs remain syntactically coherent. The system continues to run. The logs show activity, not errors. But the semantic quality of what the agent produces has drifted, degraded, or broken in ways that are invisible to standard infrastructure monitoring.
This is not a minor engineering inconvenience. It is a fundamentally different class of operational problem. And it demands a fundamentally different approach to observability, debugging, and system design.
The incident I described above falls into what I now call a **context corruption failure** — one of several distinct failure patterns I have come to recognise across AI agent deployments. Understanding these patterns is the starting point for building systems that are actually debuggable when things go wrong.
A Taxonomy of Agent Failure Modes
Before you can debug effectively, you need a vocabulary. In traditional systems engineering, we categorise failures by where they occur in the stack — network, application, database, infrastructure. For AI agent systems, I find it more useful to categorise by *how the failure propagates* and *how visible it is*.
Silent Semantic Drift
The most dangerous failure mode. The agent continues to operate but produces outputs that are subtly wrong. This typically occurs when something in the agent’s context — its memory, its instructions, or its tool outputs — changes in a way the agent cannot detect or compensate for. The agent isn’t confused; it’s confidently wrong, which is far harder to catch.
Silent semantic drift can be triggered by changes in upstream data schemas, prompt template modifications that interact unexpectedly with the model’s behaviour, model version updates from a provider that subtly shift output characteristics, or accumulated errors in a memory store that the agent reads but never validates.
Tool Failure Propagation
Modern agents use tools — APIs, databases, search interfaces, code interpreters. When a tool fails, the expected behaviour is for the agent to detect the failure and handle it gracefully. In practice, this varies widely depending on how the tool is implemented and how the agent’s error-handling logic is structured.
A tool that returns an empty result set instead of an error will not trigger exception handling. The agent will proceed on the assumption that the empty result is meaningful. Depending on the agent’s reasoning chain, this can lead to decisions that are logically coherent but factually empty — built on a foundation of nothing.
I have seen this pattern cause particularly significant problems in retrieval-augmented systems, where a degraded vector search returns low-relevance results rather than failing outright. The agent receives what appears to be information and reasons from it. The resulting outputs look well-grounded. They are not.
Instruction Conflict
When an agent operates under multiple instruction sources — a system prompt, user instructions, retrieved documents, memory outputs, and tool results — there is always the potential for these sources to provide conflicting guidance. Well-designed agents have mechanisms for resolving conflicts. Poorly designed ones proceed with whatever information is most salient in context, which is often not what you intended to prioritise.
Instruction conflicts become more frequent and more severe as agents become more complex. The more tools an agent has access to, the more memory it maintains, the more capable it is — the more opportunities there are for instruction sources to collide in ways that produce unpredictable behaviour.
State Accumulation Errors
Long-running agents, particularly those with persistent memory or those operating in loops, are vulnerable to state accumulation errors. Small inaccuracies compound over time. A slightly wrong inference gets encoded into memory. Subsequent reasoning draws on that incorrect premise. The error is amplified across subsequent interactions until the agent’s behaviour diverges significantly from intended operation.
This is analogous to floating-point drift in numerical computing — individually negligible imprecisions that accumulate into substantial errors over many operations. But in an LLM-based agent, the errors are semantic rather than numerical, which makes them harder to quantify and monitor.
The Debugging Process: How I Actually Approached It
When I investigated the incident I described at the opening of this article, I did not start with the agent. I started with the data.
This is a counterintuitive instinct for many engineers, who are trained to inspect the failing system directly. But in an agentic context, the agent itself is usually the last place the root cause will be found. The model’s reasoning capability is generally sound. The prompt template has usually worked before. The issue is almost always something in the environment the agent is operating within.
Step one: map the information flow. Before I looked at any logs or agent outputs, I traced the complete data flow from source to output. What feeds does the agent read? Where does its context come from? What tools does it call, and what do those tools read? This mapping exercise is essential because agent failures almost always originate outside the model itself — in data, tools, memory, or infrastructure.
In this case, that mapping immediately surfaced the schema change in the upstream feed. A field name had been altered during a routine data pipeline update. The agent’s context-building logic had not been updated to match. Rather than failing, it had silently fallen back to a default value — a fallback that was technically functional but semantically incorrect.
Step two: establish a ground truth baseline. Before I could confirm what was broken, I needed to know what correct looked like. I pulled a sample of agent outputs from before the incident period and compared them against outputs from the degraded period. The differences were subtle but consistent — a systematic shift in routing categorisation that would not have been visible in aggregate metrics but was clear in side-by-side comparison.
This step is frequently skipped in post-incident reviews because teams lack the tooling to make it easy. If you cannot readily compare historical agent outputs against current outputs on a like-for-like basis, you are flying blind in your debugging process. Building that capability is not optional; it is foundational.
Step three: isolate the failure to a specific component. With the schema mismatch identified and the output degradation confirmed, I needed to verify that these two facts were causally related rather than coincidentally correlated. I replicated the context-building process with the corrected schema and re-ran a sample of the agent’s recent decisions. The outputs returned to the expected patterns.
This replication step is important even when the root cause seems obvious. In complex systems, what appears to be a single cause often has multiple contributing factors. Verifying that your fix actually resolves the observed behaviour, rather than assuming it will, is essential discipline.
Step four: trace the blast radius. Once the root cause was confirmed and the fix was validated, the remaining question was scope: how many decisions had been affected, and what actions had those decisions triggered downstream? This required tracing the agent’s output logs, correlating them with downstream system states, and mapping which actions needed remediation.
This is where the real operational cost of silent failures becomes apparent. In a system that fails noisily, you can typically bound the impact by the time from failure to alert. In a system that fails silently, the impact window is the time from failure to human detection — which, in this case, was 48 hours.
A Diagnostic Framework for Agent Infrastructure
Based on this incident and several others before and since, I have developed a diagnostic framework I now apply to any agent system investigation. It is not a rigid checklist but a structured way of thinking about where to look and in what order.
The TRACE Framework
T — Trace the data flow. Start outside the model. Map every input the agent receives: system prompts, memory retrievals, tool outputs, API responses, user inputs. Identify any recent changes to any of these sources. The root cause is almost always here.
R — Reproduce the behaviour. Do not reason about what might have caused an incorrect output. Reproduce the incorrect output in a controlled environment. This confirms your hypothesis and gives you a working test case for validating the fix.
A — Audit the outputs. Establish what correct behaviour looks like and systematically compare it against the observed outputs. Quantify the deviation. This is how you measure blast radius and confirm when the fix has taken effect.
C — Check the context window. Inspect the actual prompt that was sent to the model at the time of the failure. In most LLM-based agent frameworks, this is logged or can be reconstructed. Understanding exactly what the model was given is often more informative than inspecting the model’s output in isolation.
E — Evaluate the error handling. Identify every point in the system where a failure could have been surfaced but was not — tool calls that returned unexpected results, memory queries that returned nothing, context-building steps that fell back silently. These are the observability gaps that allowed the failure to propagate undetected.
Implementation Risks and Trade-offs
I want to be direct about something that is often glossed over in technical writing about AI agents: the operational maturity required to run these systems reliably is significantly higher than most organisations assume when they decide to deploy them.
The frameworks and debugging processes I have described above are not particularly exotic. But they require investment. They require logging infrastructure that captures agent context, not just system events. They require tooling for comparing and auditing agent outputs over time. They require human reviewers with enough domain knowledge to recognise when outputs are semantically wrong rather than just syntactically invalid. And they require an organisational culture that treats AI agent outputs as something to be verified rather than assumed correct.
This last point deserves particular emphasis. One of the most significant risks in AI agent deployment is what I would call **automation complacency** — the tendency for human oversight to atrophy as agents demonstrate reliability over time. The system works well for six weeks, and people stop checking. Then when it starts working incorrectly, nobody notices for 48 hours. Or 96. Or more.
The mitigation is not heroic vigilance on the part of operators. The mitigation is systematic. Build sampling-based quality checks into the process. Define expected output distributions and alert on deviations. Establish regular human review cycles for agent decisions in high-stakes workflows, even when the system appears to be running well. Reliability should earn reduced oversight gradually and with evidence, not assume it automatically.
There is also a genuine trade-off to acknowledge between agent capability and debuggability. More capable agents — those with larger context windows, richer memory structures, broader tool access — are more powerful and more useful. They are also harder to debug when they fail, because there are more components that could be contributing to the failure and more complex interactions between them. Some organisations have found value in deliberately constraining agent capabilities below their theoretical maximum in order to maintain operational visibility. This is not a failure of ambition. It is sound systems engineering.
What This Means Strategically
The incident I started with was resolved in a day. The remediation was straightforward once the root cause was identified. The fix was a one-line schema alignment in the context-building logic. But the conditions that allowed a one-line bug to cause 48 hours of silent operational degradation were not technical — they were structural.
We had not designed sufficient observability into the system because we had not anticipated the failure modes that are specific to AI agent systems. We had excellent infrastructure monitoring. We had no semantic monitoring. That gap was not negligence; it was inexperience. We had brought traditional software reliability practices to a system that requires different ones.
The organisations that will operate AI agent infrastructure most effectively over the next several years will not necessarily be the ones that build the most sophisticated agents. They will be the ones that invest equally in the operational infrastructure that makes those agents auditable, observable, and debuggable. The intelligence layer and the reliability layer are not separate concerns — they are jointly necessary conditions for anything that can be called production-ready.
For technical leaders, the practical implication is this: when you evaluate an AI agent deployment, the evaluation criteria should not stop at capability. Does the system produce good outputs in the demo? That is necessary but insufficient. The questions that actually determine whether the system will operate reliably at scale are about observability: How will you know when it’s wrong? How quickly will you know? How will you isolate the cause? How will you bound the impact?
If you cannot answer those questions before deployment, you are accepting risks that are both avoidable and compounding. The first failure will be expensive. The second will be worse, because the first will have eroded confidence in the system’s reliability — and in your team’s ability to manage it.
Build the observability layer first. Then build the capability. In the long run, those priorities compound in your favour.